

Building a Sub-second Code Reviewer with RL
Where We Are Going Next: Sub-second, Specialized Code Review
Five second code review is fast enough to stay in flow. Sub-second is fast enough to disappear.
When review is under a second, you can run it on every autocomplete, every edit, and still never context-switch. That is the next step for us.
Note: this post describes a research prototype, not the current production system. The numbers below are from offline evaluation.
In a previous post, we talked about how kluster.ai brings automated code review from minutes down to a few seconds in your IDE. This post is about what comes next.
We have been building our own specialized review model to see whether it can match or beat larger frontier models on code review while running an order of magnitude faster. The results are promising.
Teaching Our Specialized Model to Review Code with RL
Frontier LLMs are remarkably capable at code review. But they are generalists, optimized for everything from creative writing to mathematical reasoning. You are often paying (in time and money) for capabilities you do not need.
Code review is a narrow task. You do not need a model that can compose sonnets. You need one that catches race conditions, memory leaks, and unhandled edge cases.
So we started with a smaller model, under 10 billion parameters and pretrained on code, and taught it code review through reinforcement learning. We exposed our model to real code changes, let it attempt reviews, and rewarded it when it got things right. Over time, it learned what good code review looks like.
To train and evaluate our specialized model, we used our experience from working with many codebases to build a large corpus of real world bug fix diffs and security patches across many languages and production codebases. That real world data is the backbone of the system, and we augment it with carefully designed synthetic examples to cover more surface area, rather than relying on synthetic snippets as the primary signal.
A few details for the technically curious:
- We reward our model not just for detecting an issue but for explaining it in a way that is precise, concise, and tied to a concrete fix. This keeps reported issues high signal and reduces the noisy, low value feedback that erodes trust.
- The specialization process is efficient. We can adapt the model to a new domain or customer specific dataset in hours on standard hardware, rather than months of large scale pretraining.
- Because the model is trained with reinforcement learning, its behaviour is controllable. We can bias it toward higher precision or higher recall depending on your risk appetite. A fintech team might accept more alerts around payment flows, while a fast moving product team might prefer leaner reviews that only flag the highest impact issues.
12x Faster, More Accurate
We evaluated our specialized model against a large, general-purpose baseline similar in capability to current frontier systems. The evaluation covered programming languages such as Python, JavaScript, Go, TypeScript, Java, C++, C#, Ruby, PHP, Kotlin, Swift, and Fortran, and a mix of real-world bug fixes and security vulnerabilities.
Detection is measured per bug in a PR. A detection counts only when the model flags the correct bug. It does not get credit for finding some other issue.
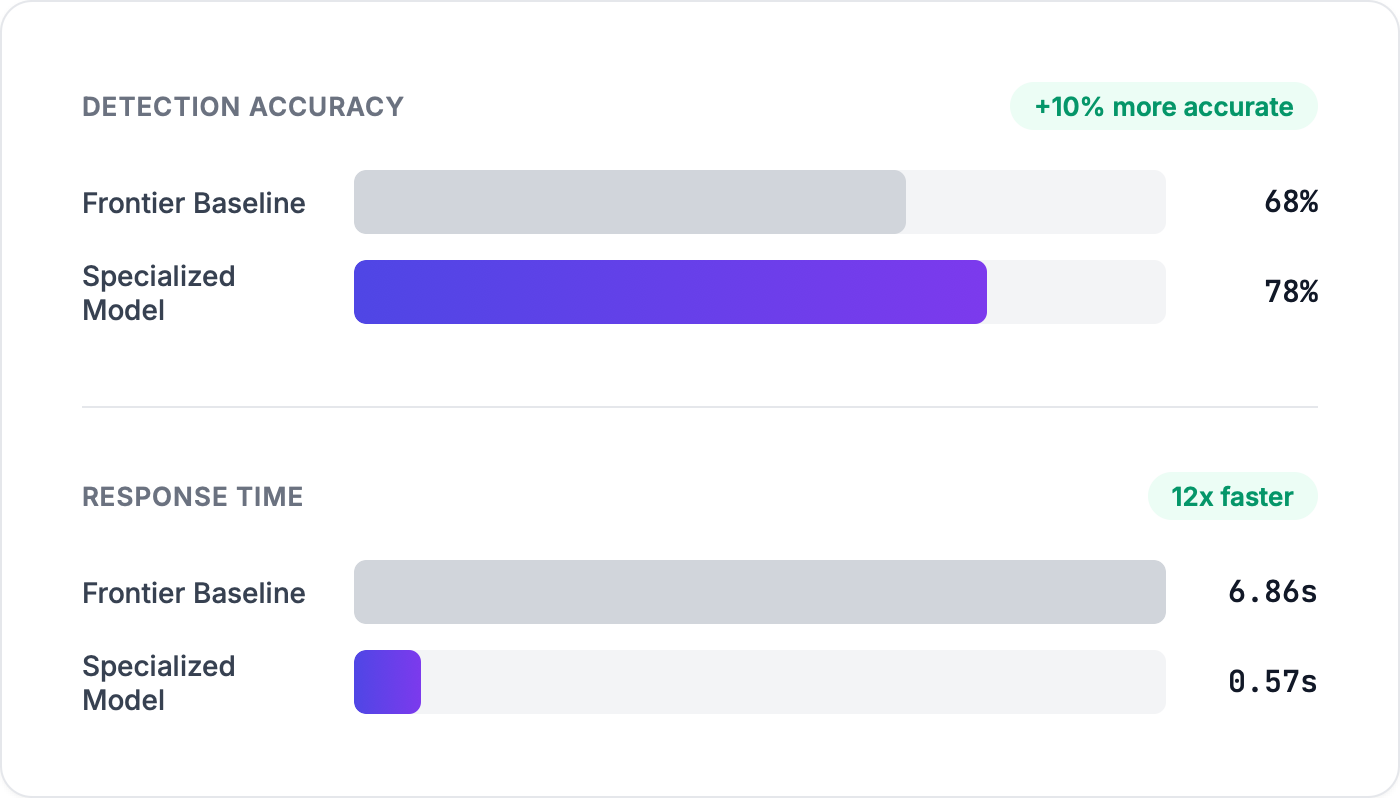
Our specialized model flags issues more accurately than the larger baseline. For this task, specialization beats scale. At 0.57 seconds versus 6.86 seconds, that is approximately 12x faster, with reviews in under a second, all while increasing the accuracy.
What This Unlocks
Sub-second review opens up use cases that even 5-second review cannot:
- Inline feedback on every autocomplete suggestion.
- Real time review of every code change.
- Pre-commit review that is effectively free.
- Multi-agent reviews where latency compounds.
In our experiments, our specialized model already matches or beats larger models on detection, but its explanations are still more generic on complex, multi-file changes. A lot of our current work is on rewarding efficient deeper reasoning and scaling to very large contexts.
We are working on bringing the best parts of this research to production. The detection and speed are there. We are now focused on making sure explanation quality and robustness match what users expect from kluster.ai. Over time, more of kluster.ai’s reviews will be powered directly by this specialized in-house model, so the gains you see in the charts here turn into better reviews in your IDE. Most teams can use kluster.ai as it ships today and get fast, accurate reviews out of the box, while still customising org/project specific rules by defining them explicitly or letting kluster.ai learn them from your existing codebase. For larger organizations that need deeper customization, strict data boundaries, or even self-hosted deployments, the same training approach lets us adapt the reviewer to your own code, rules, and environment.
If that sounds relevant for your team and you want to talk about a more tailored deployment, reach out at enterprise@kluster.ai.
The Bigger Picture
There is a common assumption in AI that bigger is always better. More parameters, more data, more compute. For broad, general-purpose tasks, that is often true.
Developer tools are different: they need to be fast, specific, and fit into a workflow without creating friction. What we are finding is that for narrow, well-defined tasks like code review, a small model trained with the right objectives can beat a much larger one, at a fraction of the latency and cost, without sacrificing the quality of the review.
The future of developer tools might not be the biggest model. We think it will be the most focused one.
Try It Free
kluster.ai brings code review down to seconds, not minutes, so you can safely review every change in your IDE. Turn it on once and get fast, accurate feedback on demand, in agent workflows, or in ambient background reviews.