

The AI Code Quality Gap: What GPT-5 and Cursor Get Wrong
The software engineering world stands at a critical crossroads. While many developers still write code the traditional way, we're witnessing an AI revolution where LLMs and AI agents are rapidly augmenting and even replacing human tasks. However, this transformation has significant challenges: AI-generated code frequently requires human intervention to meet production standards.
The Growing Problem with AI Code Generation
AI code generation tools like Cursor, VS Code Co-pilot, Claude Code, and Codex promise to revolutionize development workflows. Our analysis at kluster.ai indicates that approximately 30% of all AI agent code requests contain critical issues: bugs, security vulnerabilities, and logic problems that make the code completely unsuitable for production.
This results in substantially increased code review time. Developers spend countless hours reviewing AI-generated code, trying to make it production-ready instead of building new features. The expected productivity gains are offset by extended code review requirements.
The Performance Gap: Ranking AI Models on Code Quality
Note: This analysis is based on kluster.ai data collected between October 10-17, 2025. AI models are evolving rapidly, and by the time you read this article, the performance landscape may have changed significantly.
We analyzed the leading AI models for code generation quality, and the results are concerning.
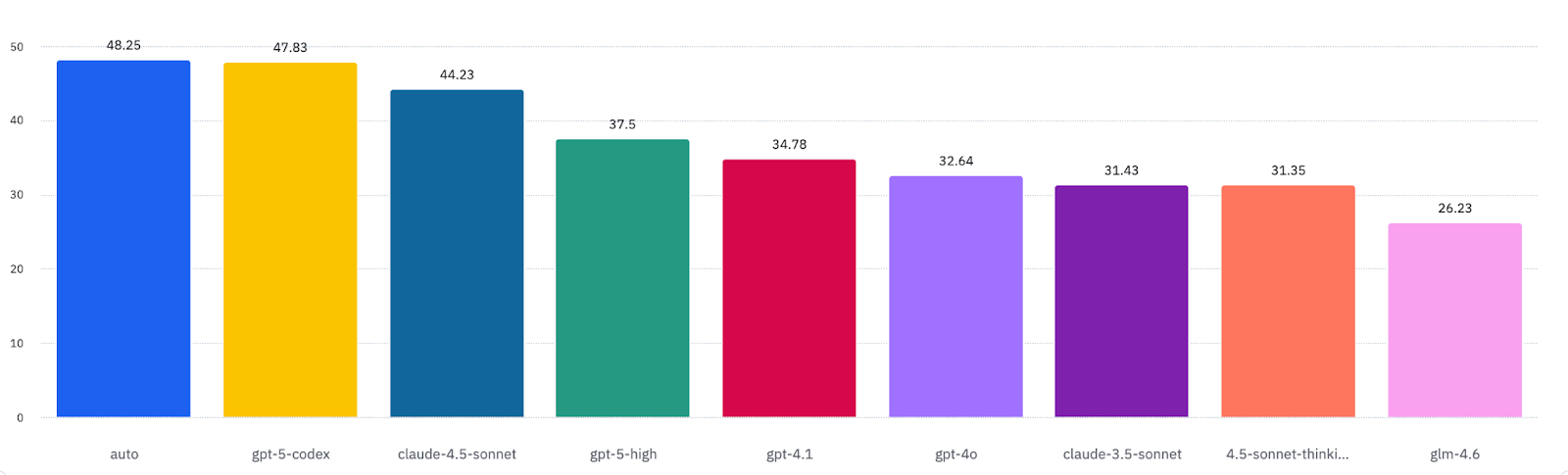
% of code reviews that identified at least 1 issue. kluster.ai data for Oct 10-Oct 17
Cursor's Auto Selection: Convenience vs. Quality
Many developers use the auto mode from Cursor which selects the best model for the task. However, unfortunately, in our data this model often results in code most likely to contain issues.
Analysis shows that 48% of code generated using Cursor's auto mode contained issues requiring correction, including critical vulnerabilities. Cursor offers intelligent model selection, but unfortunately our data shows their auto mode consistently ranks among the lowest performers in code quality.
The GPT-5 Paradox: Advanced Technology, Surprising Results
GPT-5's performance presents notable challenges. Despite being marketed as state-of-the-art for code generation, 47% of GPT-5 requests contain issues requiring fixes.
This is particularly significant given that GPT-5 represents OpenAI's latest advancement in code generation. When benchmarked against GPT-4o and GPT-4.1, GPT-5's failure rate reveals that model generation alone doesn't guarantee improved code quality.
Real-World Case Studies: GPT-5's Path from Code to Production Issues
At kluster.ai, we continuously analyze market conditions and test AI models in realistic scenarios. We put GPT-5 through rigorous testing to understand how it fails, and why automated code review is essential.
The following cases illustrate common scenarios in production environments. In each instance, kluster.ai detected and fixed issues during development, before they reached code review or deployed to production.
Case Study 1: The Database Query Nightmare
We tasked GPT-5 with creating a new page for an existing Next.js application that displays case details from an external API.
--- app/…/[caseId]/page.tsx
+++ app/…/[caseId]/page.tsx
@@
…
+ const columnSets = [
+ { label: "primary", columns: CASE_DETAIL_COLUMNS_PRIMARY },
+ { label: "fallback", columns: CASE_DETAIL_COLUMNS_FALLBACK },
+ ];
+ for (const { label, columns } of columnSets) {
+ const { data, error } = await supabaseServer
+ .from("public_cases")
+ .select(toSelectString(columns))
+ .eq("id", caseId)
+ .maybeSingle();
+
+ if (error) {
+ if (error.code === "42703" && label === "primary") {
+ console.warn(
+ "Missing 'date' column, retrying without it."
+ );
+ continue;
+ }
+ console.error("Failed to fetch case by id:", error);
+ return null;
+ }
+
+ if (data) {
+ record = data as unknown as RawCaseDetail;
+ break;
+ }
+ }kluster.ai feedback
Description
Potential N+1 query problem due to retry logic for missing 'date' column.
Explanation
The code now attempts to fetch case details with a 'primary' set of columns. If this fails with a '42703' error (undefined column) and the 'date' column is the cause, it retries the query with a 'fallback' set of columns that excludes 'date'. If the 'date' column is frequently missing in the database schema, this will result in two database queries for every case detail request, effectively doubling the database load for these specific cases. This could lead to increased latency and resource utilization on the database server.
Actions
Monitor the frequency of '42703' errors related to the 'date' column. If this error is common, consider either updating the database schema to consistently include the 'date' column or optimizing the query strategy to avoid the double fetch. For example, if the 'date' column is truly optional, a single query fetching all other necessary columns might be more efficient, and the 'date' could be handled as an optional field in the application logic without a retry.
GPT-5's Codex CLI couldn't identify the correct database table structure. Instead of properly analyzing the database schema, it generated code that:
- Makes queries with guessed column names using 2 predicted column sets
- Catches errors when columns don't exist
- Retries with a different columns
This approach creates significant performance concerns. Instead of a single database query, the system loops through multiple requests, trying different SQL parameters until something works. On production, this could cause performance degradation, higher hardware cost, or even significant downtime, turning one query into multiple queries per page load.
kluster.ai detected this issue and provided specific recommendations to GPT-5 about using correct column specifications.
The Fix That Made Things Worse
Despite receiving detailed feedback, GPT-5's automatic correction made the code even worse.
--- app/…/[caseId]/page.tsx
+++ app/…/[caseId]/page.tsx
@@
…
- const getAvailableCaseColumns = function() ….
**…**kluster.ai feedback
Description
Undefined function getAvailableCaseColumns is called, which will cause a runtime error.
Explanation
The new code introduces a call to getAvailableCaseColumns() to dynamically determine which columns are available in the database. However, the definition for getAvailableCaseColumns is not present in the provided diff or the post_diff_codebase_snippets. This will result in a runtime error (e.g., ReferenceError: getAvailableCaseColumns is not defined in JavaScript/TypeScript) when getCaseById is invoked.
Actions
Ensure that the getAvailableCaseColumns function is properly defined and imported within the scope where it is being called. Without its definition, the application will fail to fetch case details.
GPT-5 removed the method that auto-generates the column list, but completely forgot to update the code that calls this method to generate SQL queries. The result? Completely invalid, non-compilable code. The application wouldn't even start.
kluster.ai caught this compilation error and alerted Codex that the code needed fixing to be executable and logically correct.
Code Duplication: The Final Insult
Even after multiple iterations, GPT-5's final solution revealed another critical problem.
--- app/…/[caseId]/page.tsx
+++ app/…/[caseId]/page.tsx
@@
…
const getCaseById = cache(async (caseId: string): Promise<CaseDetail | null> => {
try {
+ const availableColumns = await getAvailableCaseColumns();
+ if (!cachedColumnSet) {
…kluster.ai feedback
Description
Code duplication and increased complexity in getCaseById function.
Explanation
The logic for fetching available columns from information_schema.columns was previously encapsulated in getAvailableCaseColumns. This logic has now been duplicated and inlined directly into the getCaseById function. This increases the getCaseById function's length and responsibility, making it harder to read, understand, and maintain. The same column fetching logic appears twice within the getCaseById function's scope (once for initial check, once inside the columnFetchPromise definition).
Actions
Review the getCaseById function. Consider extracting the column fetching logic into a dedicated, reusable utility function or module to avoid duplication and improve separation of concerns. This would reduce the complexity of getCaseById and make the column fetching mechanism more modular.
GPT-5 completely duplicated an entire function for two different use cases with nearly identical code. This kind of code duplication significantly degrades codebase quality and maintainability.
Thanks to kluster.ai detecting this duplication, GPT-5 refactored the code to use a single method instance instead of two copies.
Case Study 2: Desktop Notes Application Failures
To confirm these weren't isolated incidents, we tested a new desktop application—a notes and lists management system similar to a ticket management system.
The code of the new app is huge - here is an approximation of what was generated:
+import Foundation
+import SQLite3
+
+enum DatabaseError: Error {
+ case openDatabase(message: String)
+ case prepare(message: String)
+ case step(message: String)
+ case bind(message: String)
+}
+
+// [STRIPPED: LocalizedError extension with errorDescription implementation]
+
+final class DatabaseManager {
+ static let shared = DatabaseManager()
+ private let queue = DispatchQueue(label: "com.trelloboardapp.database", qos: .userInitiated)
+ private var db: OpaquePointer?
+ private let allowedPositionTables: Set<String> = ["boards", "lists", "cards"]
+ private let allowedFilterColumns: Set<String> = ["board_id", "list_id"]
+
+ private init() {
+ try openDatabase() // [STRIPPED: ~25 lines - creates app support dir, opens SQLite DB]
+ try configureDatabase() // [STRIPPED: Enables foreign keys pragma]
+ try createTables() // [STRIPPED: ~30 lines - CREATE TABLE statements for boards/lists/cards]
+ }
+
+ // [STRIPPED: deinit - closes database connection]
+ // [STRIPPED: currentErrorMessage property - gets SQLite error messages]
+ // [STRIPPED: execute(sql:) method - executes SQL without parameters]
+
+ // MARK: - Public API
+ func loadBoards(completion: @escaping (Result<[Board], Error>) -> Void)
+ func createBoard(named name: String, completion: @escaping (Result<Void, Error>) -> Void)
+ func renameBoard(id: Int64, newName: String, completion: @escaping (Result<Void, Error>) -> Void)
+ func deleteBoard(id: Int64, completion: @escaping (Result<Void, Error>) -> Void)
+ // [STRIPPED: ~15 lines per method - actual implementations with statement prep/binding/execution]
+
+ func createList(boardID: Int64, name: String, completion: @escaping (Result<Void, Error>) -> Void)
+ func renameList(id: Int64, newName: String, completion: @escaping (Result<Void, Error>) -> Void)
+ func deleteList(id: Int64, completion: @escaping (Result<Void, Error>) -> Void)
+ func persistListPositions(boardID: Int64, lists: [BoardList], completion: @escaping (Result<Void, Error>) -> Void)
+ // [STRIPPED: ~20 lines per method - transactional position updates in loop]
+
+ func createCard(listID: Int64, title: String, details: String, dueDate: Date?, completion: @escaping (Result<Void, Error>) -> Void)
+ func updateCard(card: Card, completion: @escaping (Result<Void, Error>) -> Void)
+ func deleteCard(id: Int64, completion: @escaping (Result<Void, Error>) -> Void)
+ func persistCardPositions(listID: Int64, cards: [Card], completion: @escaping (Result<Void, Error>) -> Void)
+ // [STRIPPED: ~25 lines per method - implementations with nullable due_date handling]
+
+ func moveCard(_ cardID: Int64, from sourceList: Int64, to destinationList: Int64,
+ destinationIndex: Int, completion: @escaping (Result<Void, Error>) -> Void)
+ // [STRIPPED: ~20 lines - orchestrates transaction and delegates to moveWithinSameList or moveAcrossLists]
+
+ // [STRIPPED: moveWithinSameList method - ~35 lines - shifts positions up/down within same list]
+ // [STRIPPED: moveAcrossLists method - ~30 lines - closes gap in source, opens space in dest]
+
+ // MARK: - Helpers
+ // [STRIPPED: fetchBoards() - ~15 lines - loads all boards with nested lists/cards]
+ // [STRIPPED: fetchLists(for:) - ~15 lines - loads lists for board with cards]
+ // [STRIPPED: fetchCards(for:) - ~15 lines - loads cards for list, handles nullable due_date]
+ // [STRIPPED: fetchCard(by:) - ~20 lines - single card fetch with error handling]
+ // [STRIPPED: nextPosition() - ~20 lines - calculates next position with table/column validation]
+ // [STRIPPED: cardCount(in:) - ~10 lines - counts cards in list]
+ // [STRIPPED: prepareStatement() - ~10 lines - wraps sqlite3_prepare_v2]
+ // [STRIPPED: step() - ~5 lines - wraps sqlite3_step with error check]
+ // [STRIPPED: bindText/bindInt/bindInt64/bindDouble - ~5 lines each - parameter binding helpers]
+ // [STRIPPED: performUpdate() - ~15 lines - generic async update helper with bindings closure]
+}The system failed to work on the first attempt. During implementation, kluster.ai discovered multiple issues strikingly similar to the previous case.
The Classic N+1 Problem
kluster.ai feedback
Description
N+1 Query Problem in Data Fetching
Explanation
The fetchBoards function (lines 470-484) iterates through all boards. For each board, it calls fetchLists(for: id) (line 481). Inside fetchLists (lines 486-503), it iterates through all lists and calls fetchCards(for: listID) (line 500). This results in an N+1+M query pattern, where N is the number of boards and M is the number of lists. Specifically, loading B boards requires 1 query for boards + B queries for lists + (Total number of lists) queries for cards. This sequential, nested fetching significantly increases database I/O and latency, especially for large datasets, compared to fetching all data in fewer, more complex queries (e.g., using JOINs or batching).
Actions
Refactor the data loading mechanism (fetchBoards, fetchLists, fetchCards) to use fewer database calls. Consider fetching all lists and cards in bulk and then mapping them to their respective parent boards/lists in memory, or using recursive common table expressions (CTEs) or JOINs if the SQLite version supports efficient complex queries.
GPT-5 implemented all SQLite database operations with the classic N+1 query problem, performing sorting and filtering in memory rather than at the database engine level.
While this might work with small datasets, as the number of cards grows, application performance degrades dramatically. Kluster.ai detected this during code writing and worked with the AI agent to ensure all filtering, sorting, and data processing operations executed at the database level.
Array Bounds Vulnerabilities
kluster.ai feedback
Description
Potential array index out of bounds or incorrect clamping in moveWithinSameList when calculating clampedDestination.
Explanation
In moveWithinSameList (line 400), the calculation for clampedDestination is: let clampedDestination = min(max(destinationIndex, 0), max(cardCount - 1, 0)). If cardCount is 0 (an empty list), max(cardCount - 1, 0) evaluates to max(-1, 0), which is 0. If cardCount is 1, it evaluates to 0. If the list is empty (cardCount == 0), the moveWithinSameList function should ideally not be called, or the logic should handle the empty case. If cardCount is 1, currentPosition must be 0. If destinationIndex is 0, clampedDestination is 0, and the function returns (correctly). If cardCount is > 0, the maximum valid index is cardCount - 1. However, if the list is empty (cardCount == 0), currentPosition (fetched from fetchCard) will be invalid, but assuming fetchCard ensures the card exists, cardCount must be at least 1. The issue arises if cardCount is 1, and destinationIndex is 1. clampedDestination becomes min(1, 0), which is 0. This seems overly restrictive. When moving a card, the destination index can legitimately be equal to the current count (i.e., moving to the end). The maximum valid index for insertion should be cardCount (if moving to the end of a list of size cardCount). In moveAcrossLists (line 440), the clamping is let targetIndex = min(max(destinationIndex, 0), destinationCount). This correctly allows insertion at index destinationCount (the end of the list). For moveWithinSameList, if a list has 5 cards (indices 0-4), cardCount is 5. The maximum valid index for insertion is 5 (after the last card). The current clamping max(cardCount - 1, 0) limits the destination to 4. If destinationIndex is 5, clampedDestination becomes 4, meaning a move to the end of the list is incorrectly clamped to the second-to-last position, leading to a logical error in card ordering.
Actions
Review the clamping logic in moveWithinSameList (line 400). It should likely clamp the destination index to cardCount (allowing insertion at the end) rather than cardCount - 1.
Kluster.ai discovered numerous problems in GPT-5's code, including arrays used without size validation. With large element counts, arrays could go out of bounds, causing complete application crashes.
Again, kluster.ai identified and fixed this issue during code writing, before completion.
Code Organization Challenge: Managing Large Single-Responsibility Files
kluster.ai feedback
Description
God Class / Architectural Violation: The DatabaseManager class is excessively large and handles too many responsibilities, violating the Single Responsibility Principle (SRP).
Explanation
The DatabaseManager class spans 662 lines of code and encompasses responsibilities ranging from low-level SQLite interaction (binding, stepping, error messaging, thread management) to high-level application logic (CRUD operations for three different entities: Boards, Lists, Cards) and complex transactional logic (card movement, list repositioning). This makes the class difficult to maintain, test, and extend. For example, the complex card movement logic (moveCard, moveWithinSameList, moveAcrossLists) should ideally reside in a dedicated repository or service layer, separate from the low-level connection and binding logic.
Actions
Review path only—audit affected components, assess design options, or plan incremental evaluations; do not prescribe refactors. Evaluate splitting DatabaseManager into smaller, focused components, such as a SQLiteConnectionManager (for low-level access and binding) and separate repository classes (e.g., BoardRepository, CardRepository) for entity-specific CRUD and business logic.
GPT-5's final implementation created a "database_manager" file containing virtually all business logic for database operations, queries, data retrieval, insertion, and CRUD operations. The result? A 700-line file that's impossible to maintain.
This creates two critical problems:
- Code maintainability: Working with such massive files is extremely difficult
- Vibe coding limitations: Every AI model has context window limits. Large files force IDEs to load code in chunks, degrading AI agent performance and potentially causing agents to fail or loop endlessly
kluster.ai identified this problem and suggested refactoring the class into smaller, functional files. While functionality remains unchanged, future AI sessions will work faster and more reliably with smaller, more readable files and higher-quality code.
The Truth About State-of-the-Art AI Models
These case studies demonstrate that current AI models, including GPT-5, require oversight and validation systems. AI models make crude errors that can cause catastrophic production problems, from completely non-executable code to hidden performance issues like N+1 queries.
These issues might not affect your application in staging environments, but under real production load, they can cause downtime and significant financial damage.
How kluster.ai Solves the AI Code Review Problem
kluster.ai provides a complete solution through automated code review directly within AI agents during the writing process.
Unlike traditional code review tools, kluster.ai has access to:
- Freshly written code in real-time
- The specific agent request and intent
- The agent's reasoning for implementation decisions
This massive amount of additional context allows kluster.ai to make accurate decisions about whether code is correctly implemented, identify security vulnerabilities, and ensure high-quality generated code before it appears in pull requests.
Humanize the Code: Eliminating Pull Request Hell
Our ultimate goal? Eliminate pull requests entirely, because nobody likes them.
We've solved one of the most complex components of this problem: invalid and low-quality AI-generated code. By automating code checks for security vulnerabilities, logical errors, and performance issues directly in your IDE, kluster.ai transforms AI code generation from unreliable to production-ready.
Try kluster.ai Today
Stop wasting time on endless code review of AI-generated code. Let kluster.ai automatically verify AI code generation in Cursor, VS Code, and other development environments.
Experience automated code review that actually works. Try kluster.ai today.
Ready to transform your AI-assisted development workflow? Visit kluster.ai to get started with intelligent code review for Claude, GPT-5, Co-pilot, and all major AI coding assistants.